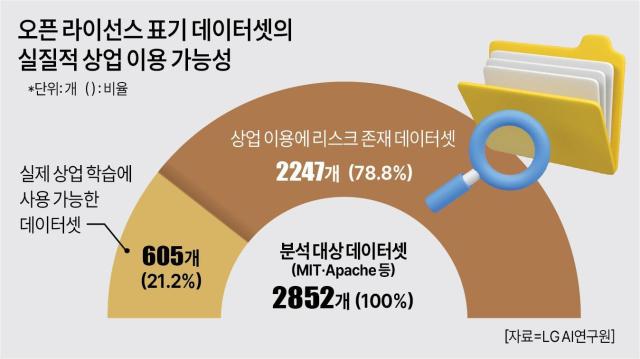
20일 LG AI연구원의 ‘AI 윤리 책무성 보고서’에 따르면, 대표 오픈 라이선스인 MIT·아파치 등으로 표기된 데이터셋(AI 학습용 데이터 묶음) 2852개를 분석한 결과 상업 학습에 실제 사용 가능한 데이터셋은 605개(21.2%)에 그쳤다.
MIT·아파치로 표기된 오픈 라이선스는 개인·상업 사용은 물론 재배포까지 모두 가능하다.
LG AI연구원은 이처럼 오픈 라이선스로 공개된 데이터라도 다른 출처 데이터(논문, 웹, 코드 등)와 섞이며 상업 사용이 제한되는 사례가 늘고 있다고 분석했다.
이 때문에 상업용 AI 개발에서는 ‘표기 확인’ 수준을 넘어, 학습 투입 전 데이터 출처와 이용 조건을 다중 확인·검증하는 과정을 반드시 거쳐야 한다는 지적이 나온다. 학습 이후 권리 조건 문제가 확인되면 사용 데이터 교체와 재학습이 불가피하다. 제품 배포 일정과 비용 부담도 동시에 커질 수 있다. 개발 조직이 데이터 확인과 승인 책임을 명확히 하지 않으면, 사전 검증 절차가 자율 준수에 머물며 이행률이 낮아질 가능성이 크다.
오픈 라이선스는 ‘저작권 면책’이 아니라 ‘조건부 허용’에 가깝다는 점도 위험을 키우는 요인이다. 상업 이용이 가능하더라도 출처 표시‧변경 고지‧재배포 조건 등 준수 의무가 따를 수 있고, 이를 놓치면 분쟁으로 전환될 수 있다.
특히 모델을 외부 서비스로 배포하거나 API(응용프로그램 인터페이스)로 제공하는 단계에서는 학습데이터의 출처·버전·사용 범위를 설명하고 증빙해야 하는 경우가 늘어난다. 학습 전후 기록을 체계적으로 남기는 체계를 갖추지 않으면 리스크 통제가 어려워질 수 있다.
LG AI연구원은 대응 방안으로 저작권·약관 리스크를 추적하는 AI 에이전트 ‘엑사원 넥서스(EXAONE Nexus)’를 제시했다. 연구원은 추적 정확도가 81%로 인간 변호사(64%)보다 높다고 설명했다. 처리 속도는 45배, 비용 효율은 700배가량이라고 밝혔다. 인간 최종 검토 원칙을 명시해 최종 판단은 사람이 내리는 구조다.
해외에선 연구 프로젝트인 ‘데이터 프로비넌스 이니셔티브’가 데이터셋의 출처·라이선스·계보를 추적해 조건에 맞는 데이터만 선별하도록 돕는 도구를 공개했다.
소프트웨어 분야에서는 시놉시스의 ‘블랙덕’ 같은 도구가 개발에 사용된 오픈소스 코드의 라이선스 조건을 자동 점검해 상업적 사용 가능 여부와 준수 의무를 미리 확인하는 데 활용되고 있다.
LG AI연구원 관계자는 “오픈 라이선스 표기만으로 상업적 활용 가능성을 판단하기 어렵다”며 “학습데이터의 출처와 조건을 사전에 확인·검증하고, 학습 전후 기록을 남기는 체계를 갖추지 않으면 서비스 단계에서 리스크가 비용과 일정으로 전가될 수 있다”고 말했다.

한영훈 기자han@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



