
KT가 자사 거대언어모델(LLM) '믿:음 2.0'을 소개했다. 이를 기반으로 정부의 독자 인공지능(AI) 파운데이션 모델 프로젝트에 참여할 계획이다.
3일 KT는 믿:음 2.0을 소개하는 온라인 설명회를 열었다. 신동훈 KT 기술혁신부문 상무(CAIO)는 "믿:음 2.0을 기반으로 정부의 독자 AI파운데이션 모델 프로젝트에 참여할 것"이라며 "믿:음 2.0을 구현하기 위해 1년 간 노력을 거쳐 구축한 데이터들이 큰 강점이 될 것"이라고 말했다.
KT는 지난 2022년 '믿:음'을 상용화하며 AI컨택센터(AICC) 사업에 활용한 바 있다. 믿:음 2.0은 115억 파라미터 규모 '믿:음 2.0 베이스'과 23억 파라미터 규모의 '믿:음 2.0 미니'로 모두 한국어와 영어를 지원한다.
믿:음 2.0 베이스는 범용 서비스에 적합하다. 한국어 지식과 문서 기반 질의 응답에 특화한 성능을 보여준다. 믿:음 2.0 미니는 베이스 모델에서 증류한 지식을 학습한 소형 모델이다.
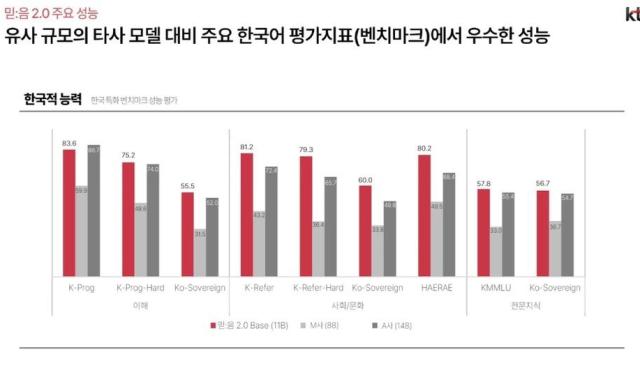
KT에 따르면 믿:음 2.0은 한국어 사회·문화 이해에 특화됐다. 고려대학교와 KT가 함께 개발한 한국어 AI 역량 평가 지표인 '코-소버린’ 벤치마크의 사회문화 항목에서 경쟁사 A사의 모델보다 약 10점 높은 60점을 기록했다.
신 상무는 "한국적 가치에 중점을 두고 튜닝했다"며 "한국 문화, 역사와 관련한 질문에 답변을 잘하고, 한국적 뉘앙스나 미세한 감정 표현 또한 잘 캐치한다"고 설명했다.
데이터 측면에서도 KT는 법적 문제 없이 사용할 수 있는 고품질 데이터를 학습에 활용했다고 강조했다. 신 상무는 "공개된 데이터 중에서도 상업적 이용이 불가능하거나 라이센스가 불투명한 데이터는 학습에 제외했다"며 "투명한 라이센스를 가진 데이터만 활용했고, 원천 데이터 가공에만 6개월 이상 소요됐다"고 언급했다.
이와 함께 KT는 마이크로소프트(MS)와 협업한 한국형 AI 모델도 준비 중이다. 신 상무는 "MS와 협력은 또 다른 방향의 모델이다"며 "고객이 상황과 목적에 맞게 쓸 수 있는 다양한 모델들을 제공해야 하는 것이 저희의 목표다"고 했다.
이어 "자체 기술을 포기해야한다고 생각한 적 없으며 기간통신사업자로 생성형AI 원천 기술을 확보해야 한다고 본다"고 덧붙였다.
KT는 믿음을 기반으로 공공, 금융 시장을 우선 공략하고 이후 교육, 법률 서비스로 확장할 계획이라고 밝혔다.
신 상무는 "모델 하나로 특정 사업자를 타겟팅하기는 어렵다"며 "내부적으로 소비자에게 어떻게 서비스할 지 고민 중이며 추후 로드맵을 공개할 것"이라고 언급했다.
믿:음 2.0의 오픈소스는 4일 AI 개발자 플랫폼 허깅페이스를 통해 공개될 예정이다.
한편 이날 SK텔레콤(SKT)가 공개한 '에이닷엑스(A.X) 4.0'과 관련해서 직접적인 비교에 대해서는 선을 그었으나 개발 방식에 차이가 있다고 밝혔다.
신 상무는 "모델의 크기가 다르기 때문에 성능을 직접적으로 비교하는 것은 의미가 없다고 생각한다"며 "다만 SKT의 모델은 중국의 알리바바 큐웬모델을 바탕으로 중간 단계부터 데이터 학습을 시킨 모델이고 믿:음의 경우 KT가 제작한 순수 자체 모델"이라고 이야기했다.

©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



