
SK텔레콤은 과학기술정보통신부가 추진한 ‘독자 AI 파운데이션 모델’ 프로젝트에 참여하며, 한국어 중심 AI 기술 자립 노력이 본격적인 결실을 맺을 것으로 기대된다고 24일 밝혔다.
SKT는 2018년부터 생성형 AI 기술이 주목받기 시작한 시점에 맞춰 한국어 특화 AI 연구에 착수, 자연어 이해 및 생성 기술을 독자적으로 고도화해왔다. 그간 축적한 기술 역량을 바탕으로 다양한 한국어 기반 초거대 언어 모델(LLM)을 자체 개발하고, 오픈소스 공개와 상용 서비스 적용을 병행하며 국내 AI 생태계의 기술 자립을 주도해왔다.
대표적으로 SKT는 2019년 국내 최초의 한국어 딥러닝 언어모델 ‘KoBERT’를 자체 개발해 고객센터 챗봇 등에 적용한 데 이어, 2020년에는 GPT-2 기반 한국어 모델 ‘KoGPT2’, 요약 특화 모델 ‘KoBART’ 등을 잇달아 선보이며 자연어 처리 기술을 한 단계 끌어올렸다. 이들 모델은 한국어의 고유한 언어 구조를 반영한 점에서 기술적 의미가 크다는 평가다.
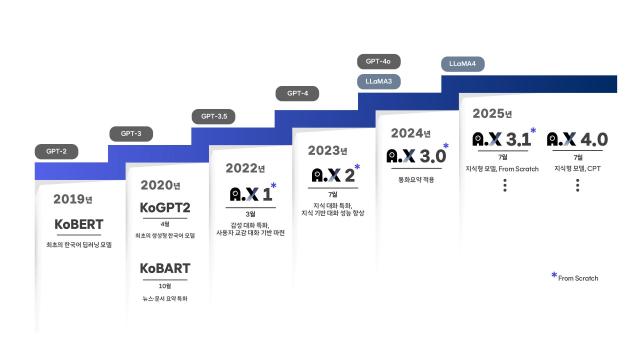
상용화 모델로는 A.X 시리즈가 있다. 2022년 ‘A.X 1’을 시작으로 감성 대화 기능을 갖춘 한국어 특화 GPT-3 모델을 선보인 데 이어, 2023년에는 문맥 이해 및 지식 응답이 가능한 ‘A.X 2’, 2024년에는 70억(7B)·340억(34B) 파라미터 규모의 ‘A.X 3.0’을 공개하며 모델 성능을 고도화했다. A.X 3.0은 통화 요약, AI 에이전트 기능 등에 적용돼 실제 서비스에서도 활용되고 있다.
올해 7월에는 외부 지식 기반 추론 기능을 강화한 ‘A.X 4.0’을 출시했다. 이 모델은 지속 학습(CPT, Continual Pre-Training) 방식을 통해 성능을 끌어올리는 한편, 데이터 보안성과 로컬 운영 가능성까지 고려한 것이 특징이다. 이어 같은 달, 3.0 계열의 고도화 버전인 ‘A.X 3.1’도 공개하며 AI 모델의 성능 다양화에 나섰다.
SKT는 이처럼 ‘프롬 스크래치(From Scratch)’ 방식의 독자 개발 모델과 CPT 방식의 대규모 지식 학습 모델을 병행하는 ‘투트랙 전략’을 통해 서비스 목적과 성능 특성에 맞춘 최적화된 AI 포트폴리오를 구축 중이다. 이를 통해 단순 질의응답을 넘어, 사용자 의도와 맥락까지 이해하는 고도화된 대화를 구현하고 있다는 설명이다.
SKT 관계자는 “AI 기술의 일상화와 산업화를 가속화하기 위해 한국어 특화 초거대 AI 모델을 지속적으로 고도화하고, 국내 생태계와의 기술 공유와 협력도 강화해 나갈 것”이라고 밝혔다.

최연재 기자ch0221@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



