카카오는 12일 테크블로그를 통해 △통합 멀티모달 언어모델(사람처럼 대화·이해하는 AI 뇌 역할) ‘카나나-o’ △이미지 검색용 멀티모달 임베딩(컴퓨터가 텍스트·이미지를 숫자 벡터로 바꿔 이해하는 방식) 모델 ‘카나나-v-임베딩’을 소개했다.
카나나-o는 텍스트·음성·이미지를 동시에 이해하고 실시간으로 답한다. 기존 모델들이 음성 대화에서는 답변이 단순해지는 한계를 보였던 것과 달리, 사용자의 숨은 의도까지 파악하는 ‘지시 이행 능력’을 강화했다. 뉴스 요약, 감정·의도 해석, 오류 수정, 형식 변환, 번역 등 다양한 작업도 수행할 수 있다.
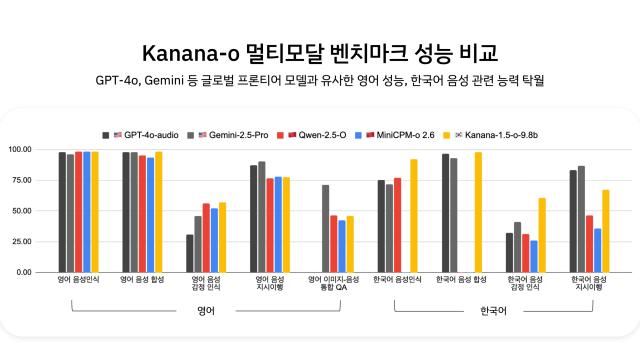
카카오는 여기에 고품질 한국어 음성 데이터와 DPO(사람이 선호하는 답변을 더 잘 따르도록 조정하는 학습법)를 적용해 억양·감정·호흡 등을 정교하게 학습시켰다. 이 효과로 기쁨·슬픔·분노·공포 등 감정 표현이 자연스러워졌고, 팟캐스트처럼 여러 차례 오가는 멀티턴(여러 번 주고받는) 대화도 끊김 없이 이어갈 수 있다. 벤치마크(표준 테스트) 결과, 영어 음성에서는 GPT-4o와 비슷한 수준, 한국어 음성 인식·합성과 감정 인식에서는 더 높은 성능을 보였다.
카카오는 앞서 공개한 언어모델 ‘카나나-1.5’를 바탕으로, 스마트폰 등에서 직접 돌아가는 온 디바이스(클라우드 접속 없이 기기 안에서 바로 실행되는) 멀티모달 모델 경량화 연구도 진행 중이다. 여러 전문가 네트워크를 섞어 쓰는 MoE(효율적으로 성능을 높이는 모델 구조) 방식의 차세대 모델 ‘카나나-2’ 개발도 준비하고 있다.
김병학 카카오 카나나 성과리더는 “카카오의 자체 AI 모델 카나나는 단순 정보 나열을 넘어, 사용자의 감정을 이해하며 친숙하고 자연스럽게 대화하는 AI를 지향한다”며 “실제 서비스에 적용해 이용자 일상 속에서 사람처럼 상호작용하는 AI 경험을 만들겠다”고 말했다.

한영훈 기자han@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



